Translations;
Event-Driven Architecture: Mikroservis mimarisinde başka servislerin verilerine mi ihtiyacınız varEvent-Driven Architecture: Do you need other service’s data in microservice architecture
In applications developed with microservice architecture, domains are generally tried to be strictly separated from each other. In the example we will examine, all logic and data related to the product are located in the product service, while the organization service that manages the sales consultants who can create orders with this product also hosts its own logic and data.
However, the createUnit() request we will make to create a sales consultant in the organization service will need the data of the product service for validation reasons. Shouldn’t the unit be given the permission to create a product that doesn’t exist? In this case, the organization service will need the data of the product service, which is not in its domain and is not under its responsibility.
We can access this data either synchronously or asynchronously. First, we’ll look at accessing it synchronously and the problems we may encounter, then we’ll address the potential issues with using the asynchronous method. Let’s begin.
Synchronous communication⌗
With the request we will send to our organization service via REST, we will trigger the createUnit() method and create a unit. However, since this service will need product data for validation purposes, it will need to retrieve this data synchronously through an HTTP REST getProduct() request.
During runtime, for the createUnit() method to be processed, both the organization service and the product service need to be up and accessible, and there must be no issues with the network connection between them. If the product service is not operational, the organization service will also not function. Even when both services are up and accessible, if the product service is slow, the synchronous request flow will be blocked, causing the organization service to slow down as well. To overcome this issue, the organization service will need to scale during periods of high demand. However, since the product service has a runtime dependency, it will also need to be scaled in the same way to handle the large number of requests coming from the organization. If we apply this practice to all services, all services will need to scale together. As a result, the organization service will be highly dependent on the product service, and they will have to continue operating together rather than independently. If all the services in our microservice architecture become dependent on each other in this way, the inaccessibility of a single service could lead to all other services becoming inaccessible as well.
During design time, if a change is made to the getProduct() API in the product service, the developers of the organization service would also need to update their HTTP client integrations accordingly. This change would likely require modifying the organization service’s codebase as well.
In conclusion, since coupling will occur both at runtime and design time, the two services will be tightly coupled, leading to what Jonathan Tower calls a distributed monolith. Any change in one service will directly affect the other, making it difficult to quickly respond to constantly changing business requirements. Any improvements made to the getProduct() method in the product service would also need to be implemented by the other services that consume it. After completing these updates, all services connected synchronously must be accessible for end-users to use the application.
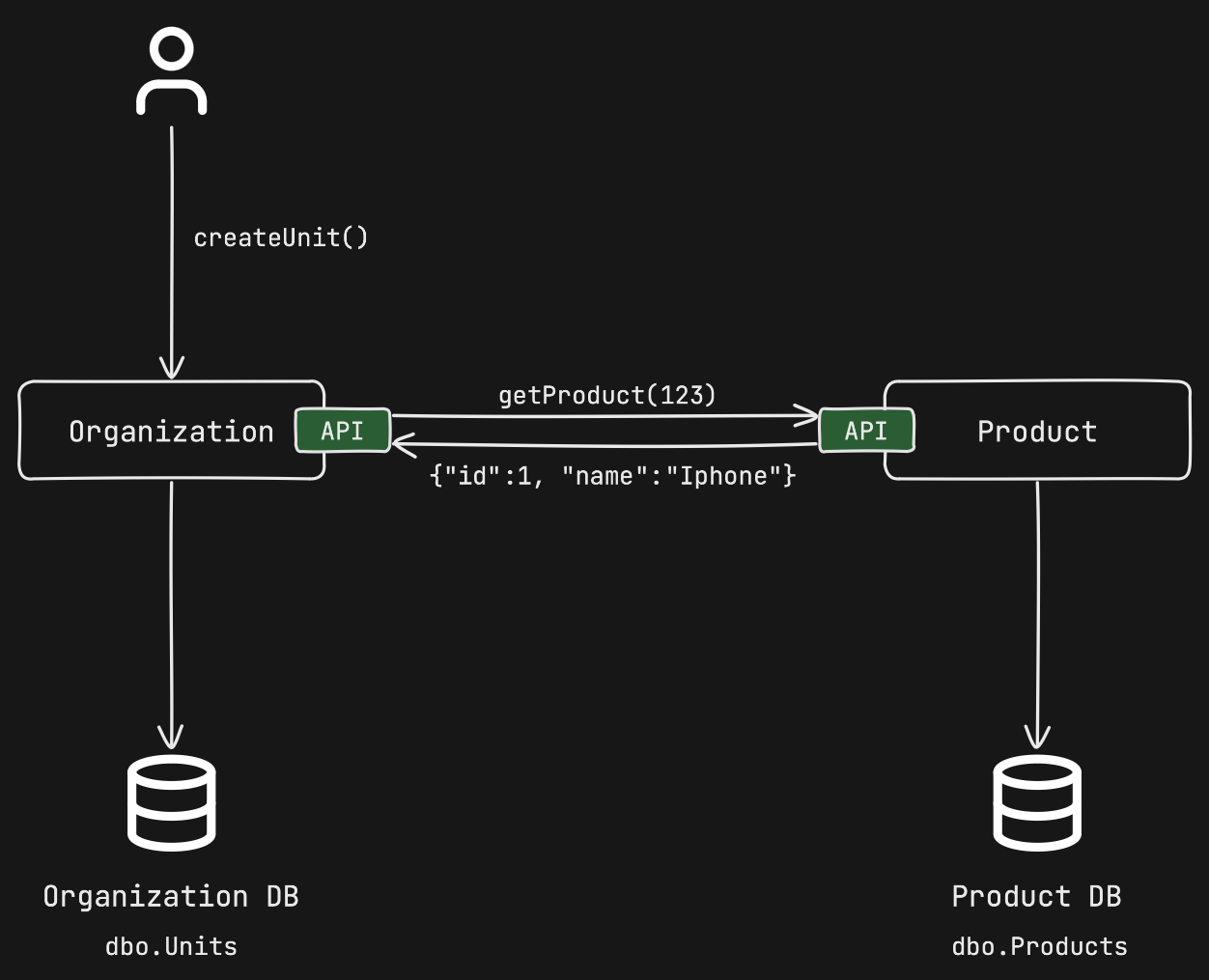
Synchronous communication
In a scenario where we want to guarantee an SLA to our customer, if we optimistically offer a 99.5% uptime guarantee for both the product and organization services, we are accepting that there could be up to 43 hours of downtime annually. In a scenario where the product and organization services are dependent on each other during runtime, using the calculation $0.995 * 0.995 = 0.990$, the dependency created by synchronous communication results in our services offering twice the downtime guarantee, potentially leading to 87 hours of downtime annually.
| Product | Organization | Product & Organization | |
|---|---|---|---|
| Uptime percentage | 99.5 | 99.5 | 99.0 |
| Month | 716 | 716 | 712 |
| Downtime in month | 4 | 4 | 7 |
| Year | 8716 | 8716 | 8672 |
| Downtime in year | 43 | 43 | 87 |
So, how do we avoid this method, which can cause so many headaches? Let’s look at another solution for communication between services.
Asynchronous communication⌗
If we don’t want to choose synchronous communication, which increases inter-service dependency in every possible direction, we can proceed with the alternative: asynchronous communication. By reversing the arrows with this method, the product service publishes a domain event called ProductCreatedEvent whenever there is an update in the product table. All services listening to this event update their own local products tables.
When the organization service needs product data, it reads from its own products table. This table is unaffected by the organization’s workflows and is only read from. This way, in the createUnit() method, we query the product data from the same database where we save the unit data.
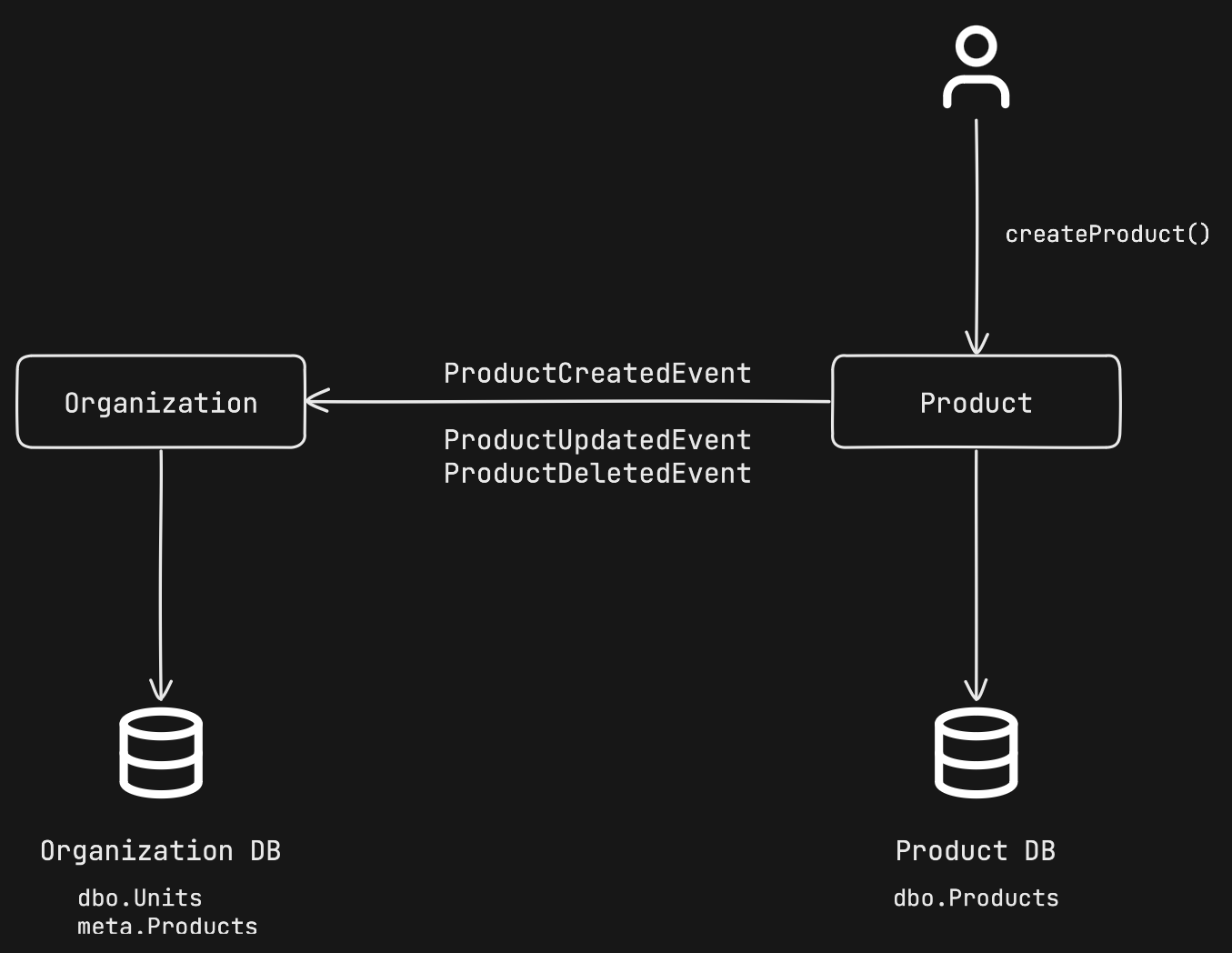
Asynchronous communication
With this method, we access the product data from the organization’s database in the createUnit() flow, eliminating runtime dependency on the product service.
By eliminating runtime dependency, we stop making synchronous queries to the product service’s getProduct() endpoint. At design time, the dependency we faced while developing is also removed. After making a change in the getProduct() method of the product service, the team managing the organization service no longer needs to make any changes.
During design time, we only have an asynchronous dependency, and we only need to make changes when necessary. If a new column is added to the product domain model, it can be added directly to the event as a new field. If a column is removed from the product table, it can be sent with default values without being removed from the event type and marked as obsolete. Services can respond to these added or removed columns as needed or continue without making any changes.
The product service does not need to care about who is processing the published event. Anyone who needs this data can consume the event, maintain their own copy of the product data, and carry on their work without having to synchronize communication with the product service. This leads to more scalable and accessible applications since they can now operate independently without depending on other services.
If we worry that our tables will mix domains, we can keep tables from different domains in a separate database schema as shown in the example below.
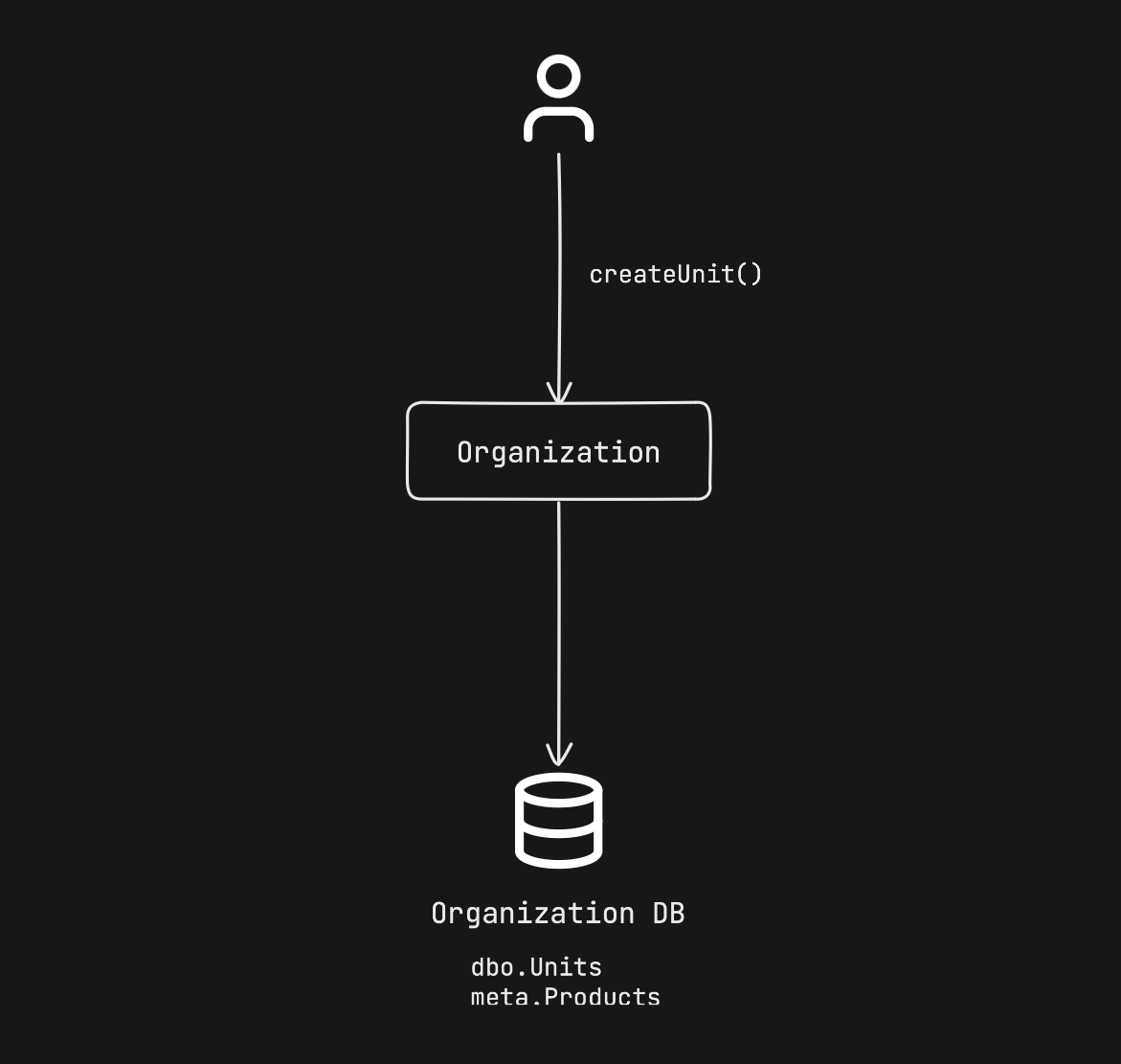
Asynchronous communication 2
Eventual consistency⌗
The biggest issue that may arise from this method is eventual consistency. The update of the relevant table in the organization service may not reflect at the exact same moment a product is added to the product service. Depending on the availability of the message broker, there could be a delay of a few milliseconds or seconds.
We can also explain this situation with CAP theory. If we keep the Partition tolerance leg, which is one of the 3 legs of CAP theory, constant, one of the Consistency and Availability legs will increase while the other will decrease. Therefore, we will not be able to provide these three options at the same time. Here, we need to decide according to the workflow we are working with.
For example, in an e-commerce system, the “add to cart” feature might need to be highly available. If the “add to cart” feature isn’t working, receiving an error message like “please try again later” might cause customers to switch to a competitor’s site. However, if we see 2 instead of 1 of the same item in our cart, we can simply adjust our cart and continue the payment process.
However, the same approach may not work for hotel reservations. In contrast to the cart example, consistency is probably more critical. Returning an error message like “please try again later” is much more logical than renting out the same room to multiple customers.
In conclusion, synchronous communication is suitable for workflows that need immediate consistency, while asynchronous communication is better for workflows that require high availability. Typically, in microservice architecture, high availability is preferred, as synchronous communication tightly couples all services together.

High availability vs Immediate consistency
Edge cases in asynchronous communication⌗
If you have decided to proceed with event-driven architecture in the communication between your services, you will need to do something to ensure data consistency in the system. If a create request comes to one of our services and we publish CreatedEvent, we first update the database and then publish the event, if the transaction we execute in the database results in an error, and we publish the event without following it, or if the transaction we execute in the database results in success but the event bus cannot be accessed afterwards, the data that is distributed in our applications may fall into an inconsistent state. In order to prevent this situation, while the product service updates the product data in its own database, it also adds the relevant event to the outbox table in the same database, and then a different thread continuously scans this table and publishes the new events. Since the record we make to the database will be processed atomically, it is guaranteed that the event data will be created in the outbox table while the product data is being created. However, in an application that works as multiple instances, situations such as an event reading from the same outbox table twice and publishing it twice may be encountered. In this case, the idempotency problem already arises.
If the result of a method being called once is the same as the result of multiple calls, then this is an idempotent method. In order to prevent an event from being processed multiple times due to different reasons and thus disrupting data consistency in the system, we will need to save the unique message id values of the events to the database after they are consumed, and continue processing if the message id value is not in the database when a new event is to be consumed. Chris Richardson (microservices.io) also touches on this issue in his article Pattern: Idempotent Consumer.
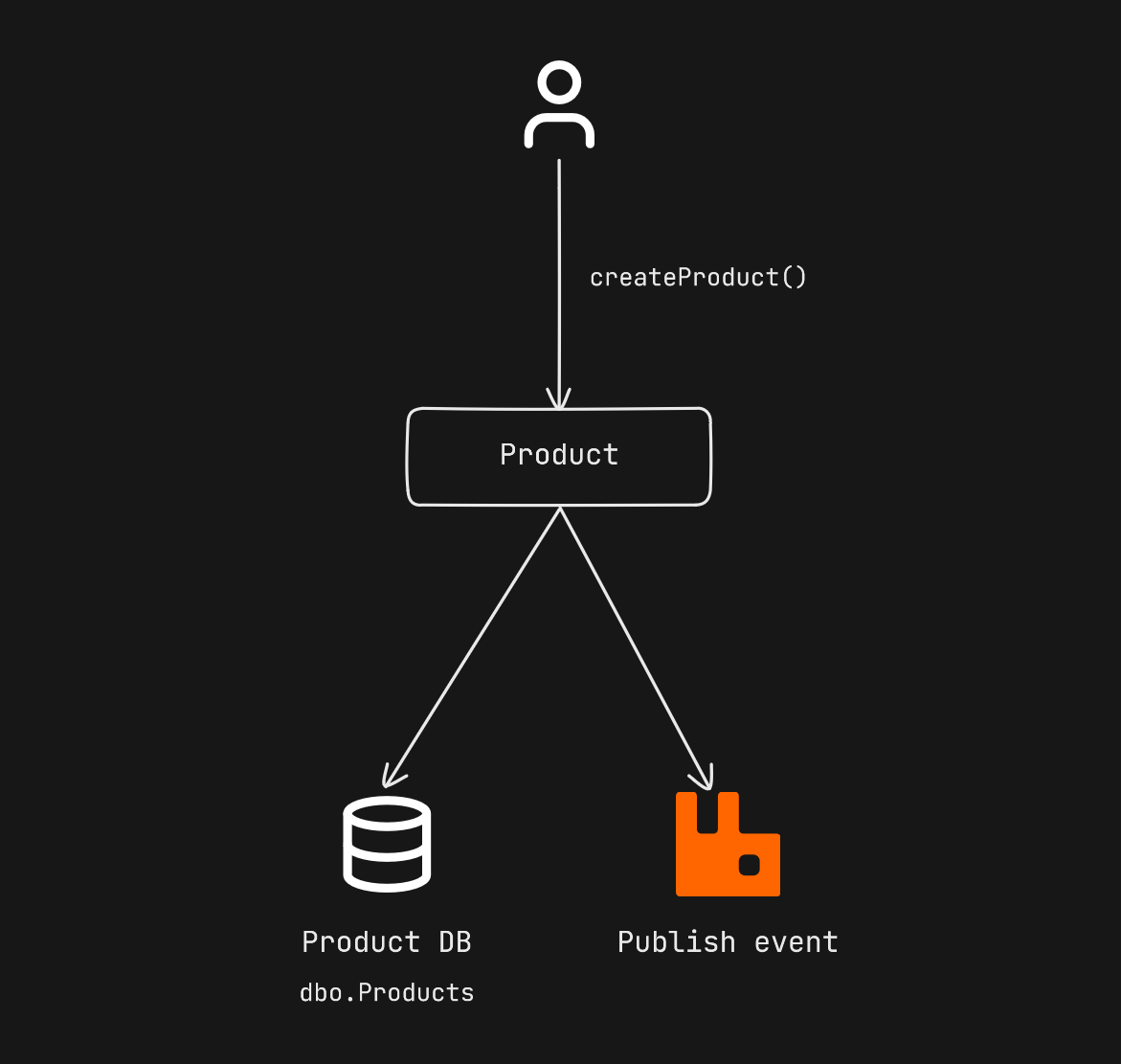
Without Outbox & Idempotency
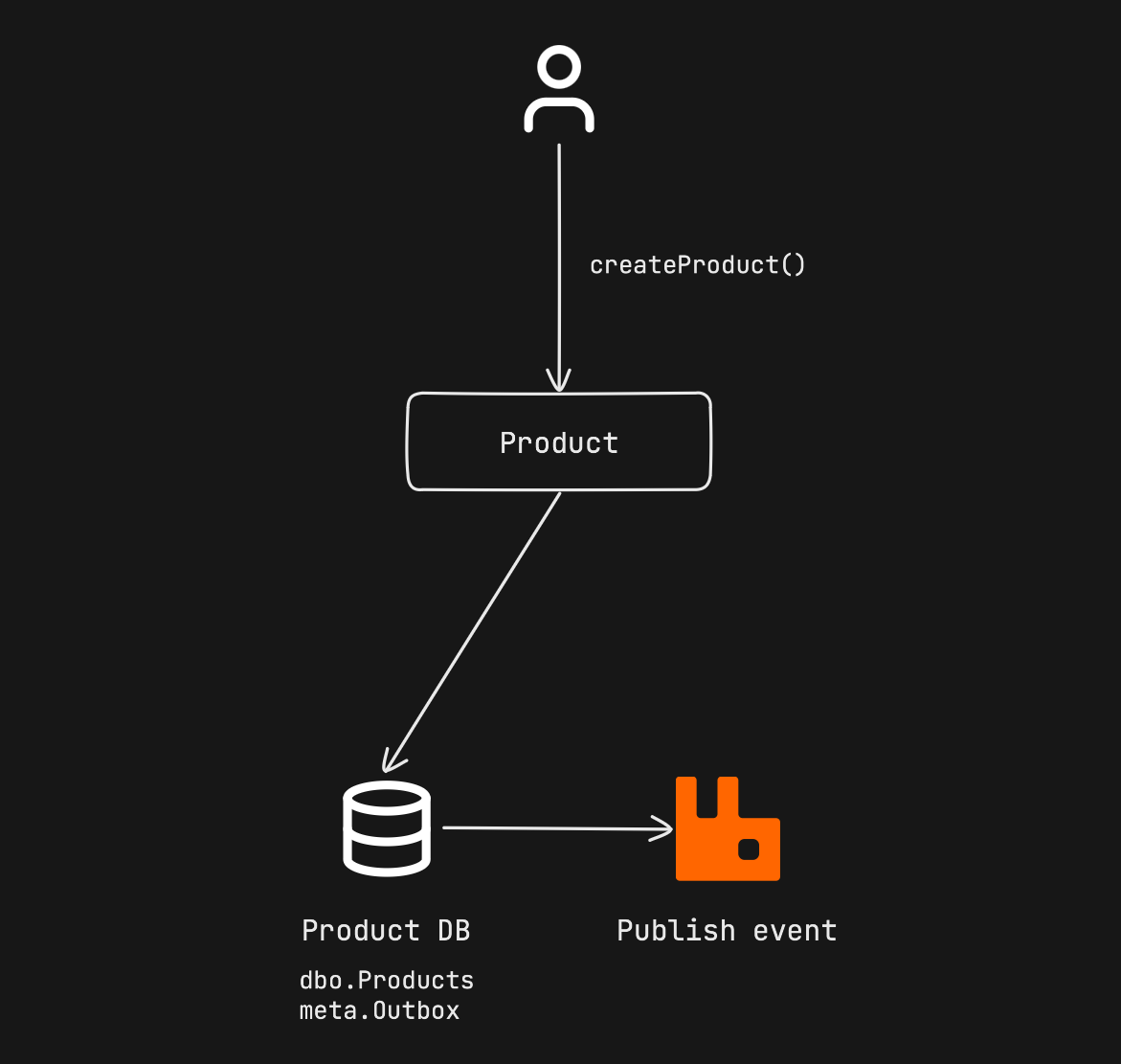
Outbox & Idempotency
As a result, as with most solutions to problems in the field of Computer Science, we do not have a silver bullet. After considering the advantages and disadvantages of both methods in detail and in the domain we are working in, we can continue with the method we want. However, my suggestion would be to eliminate the dependency between services by using asynchronous communication whenever possible.
You can access the .NET project I developed to simulate situations that may occur while working with asynchronous and synchronous data communication from the github repo below. In the example, the infrastructure provided by MassTransit was used for the outbox structure, and no special development was made for this feature.
GitHub - berkslv/lecture-fetch-other-service-data-with-event-driven-architecture
Resources⌗
Don’t Build a Distributed Monolith - Jonathan “J.” Tower - NDC London 2023
The Many Meanings of Event-Driven Architecture • Martin Fowler • GOTO 2017
Solving distributed data problems in a microservice architecture | Microservices.io
You Keep Using That Word • Sam Newman • GOTO 2023
Microservices Pattern: Pattern: Idempotent Consumer
Conclusion⌗
Thank you for reading! 🎉 In order not to miss my research in the field of software development, you can follow me at @berkslv.